
科学家之一。
-
 CVPRDeeply Learned Face Representations Are Sparse, Selective, and Robust
CVPRDeeply Learned Face Representations Are Sparse, Selective, and Robust时间:2015年丨作者:Yi Sun, Xiaogang Wang, Xiaoou Tang
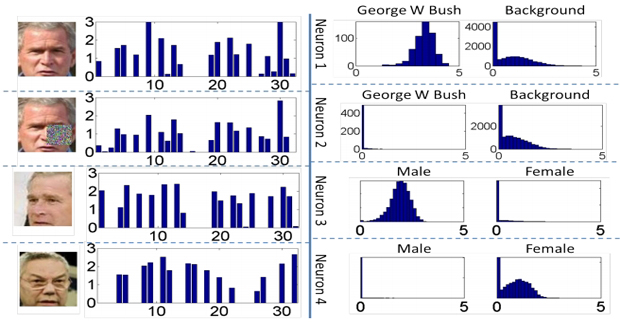
This paper designs a high-performance deep convolutional network (DeepID2+) for face recognition. It is learned with the identification-verification supervisory signal. By increasing the dimension of hidden representations and adding supervision to early convolutional layers, DeepID2+ achieves new state-of-the-art on LFW and YouTube Faces benchmarks. Through empirical studies, we have discovered three properties of its deep neural activations critical for the high performance: sparsity, selectiveness and robustness. (1) It is observed that neural activations are moderately sparse. Moderate sparsity maximizes the discriminative power of the deep net as well as the distance between images. It is surprising that DeepID2+ still can achieve high recognition accuracy even after the neural responses are binarized. (2) Its neurons in higher layers are highly selective to identities and identity-related attributes. We can identify different subsets of neurons which are either constantly excited or inhibited when different identities or attributes are present. Although DeepID2+ is not taught to distinguish attributes during training, it has implicitly learned such high-level concepts. (3) It is much more robust to occlusions, although occlusion patterns are not included in the training set.
了解更多 -
 CVPRLearning Deep Representation for Imbalanced Classification
CVPRLearning Deep Representation for Imbalanced Classification时间:2016年丨作者:Chen Huang, Yining Li, Chen Change Loy, Xiaoou Tang;
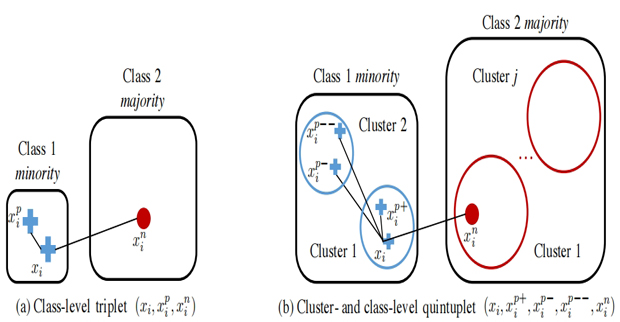
Data in vision domain often exhibit highly-skewed class distribution, i.e., most data belong to a few majority classes, while the minority classes only contain a scarce amount of instances. To mitigate this issue, contemporary classification methods based on deep convolutional neural network (CNN) typically follow classic strategies such as class re-sampling or cost-sensitive training. In this paper, we conduct extensive and systematic experiments to validate the effectiveness of these classic schemes for representation learning on class-imbalanced data. We further demonstrate that more discriminative deep representation can be learned by enforcing a deep network to maintain both inter-cluster and inter-class margins. This tighter constraint effectively reduces the class imbalance inherent in the local data neighborhood. We show that the margins can be easily deployed in standard deep learning framework through quintuplet instance sampling and the associated triple-header hinge loss. The representation learned by our approach, when combined with a simple k-nearest neighbor (kNN) algorithm, shows significant improvements over existing methods on both high- and low-level vision classification tasks that exhibit imbalanced class distribution.
了解更多 -
 IEEEFace Photo-Sketch Synthesis and Recognition
IEEEFace Photo-Sketch Synthesis and Recognition时间:2008年丨作者:Xiaogang Wang; Xiaoou Tang
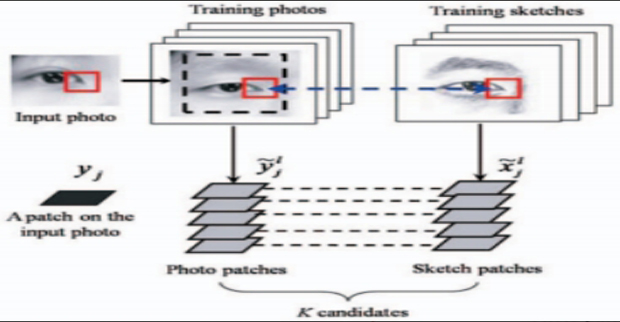
In this paper, we propose a novel face photo-sketch synthesis and recognition method using a multiscale Markov Random Fields (MRF) model. Our system has three components: 1) given a face photo, synthesizing a sketch drawing; 2) given a face sketch drawing, synthesizing a photo; and 3) searching for face photos in the database based on a query sketch drawn by an artist. It has useful applications for both digital entertainment and law enforcement. We assume that faces to be studied are in a frontal pose, with normal lighting and neutral expression, and have no occlusions. To synthesize sketch/photo images, the face region is divided into overlapping patches for learning. The size of the patches decides the scale of local face structures to be learned. From a training set which contains photo-sketch pairs, the joint photo-sketch model is learned at multiple scales using a multiscale MRF model. By transforming a face photo to a sketch (or transforming a sketch to a photo), the difference between photos and sketches is significantly reduced, thus allowing effective matching between the two in face sketch recognition. After the photo-sketch transformation, in principle, most of the proposed face photo recognition approaches can be applied to face sketch recognition in a straightforward way. Extensive experiments are conducted on a face sketch database including 606 faces, which can be downloaded from our Web site (http://mmlab.ie.cuhk.edu.hk/facesketch.html).
了解更多 -
 CVPRSpindle Net: Person Re-Identification With Human Body Region Guided Feature Decomposition and Fusion
CVPRSpindle Net: Person Re-Identification With Human Body Region Guided Feature Decomposition and Fusion时间:2017年丨作者:Haiyu Zhao, Maoqing Tian, Shuyang Sun, Jing Shao, Junjie Yan, Shuai Yi, Xiaogang Wang, Xiaoou Tang
Person re-identification (ReID) is an important task in video surveillance and has various applications. It is non-trivial due to complex background clutters, varying illumination conditions, and uncontrollable camera settings. Moreover, the person body misalignment caused by detectors or pose variations is sometimes too severe for feature matching across images. In this study, we propose a novel Convolutional Neural Network (CNN), called Spindle Net, based on human body region guided multi-stage feature decomposition and tree-structured competitive feature fusion. It is the first time human body structure information is considered in a CNN framework to facilitate feature learning. The proposed Spindle Net brings unique advantages: 1) it separately captures semantic features from different body regions thus the macro- and micro-body features can be well aligned across images, 2) the learned region features from different semantic regions are merged with a competitive scheme and discriminative features can be well preserved. State of the art performance can be achieved on multiple datasets by large margins. We further demonstrate the robustness and effectiveness of the proposed Spindle Net on our proposed dataset SenseReID without fine-tuning.
了解更多 -
 CVPRA Large-Scale Car Dataset for Fine-Grained Categorization and Verification
CVPRA Large-Scale Car Dataset for Fine-Grained Categorization and Verification时间:2015年丨作者:Linjie Yang, Ping Luo, Chen Change Loy, Xiaoou Tang
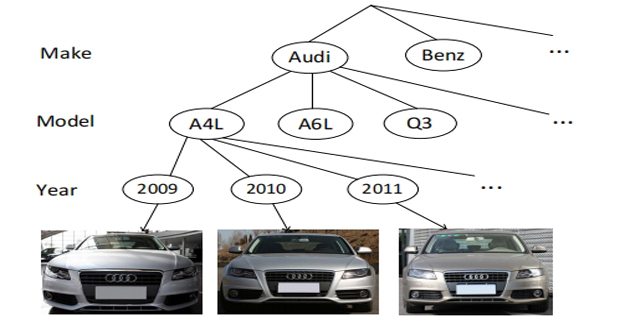
This paper aims to highlight vision related tasks centered around "car", which has been largely neglected by vision community in comparison to other objects. We show that there are still many interesting car-related problems and applications, which are not yet well explored and researched. To facilitate future car-related research, in this paper we present our on-going effort in collecting a large-scale dataset, "CompCars", that covers not only different car views, but also their different internal and external parts, and rich attributes. Importantly, the dataset is constructed with a cross-modality nature, containing a surveillancenature set and a web-nature set. We further demonstrate a few important applications exploiting the dataset, namely car model classification, car model verification, and attribute prediction. We also discuss specific challenges of the car-related problems and other potential applications that worth further investigations. The latest dataset can be downloaded at http://mmlab.ie.cuhk.edu.hk/datasets/comp_cars/index.html
了解更多 -
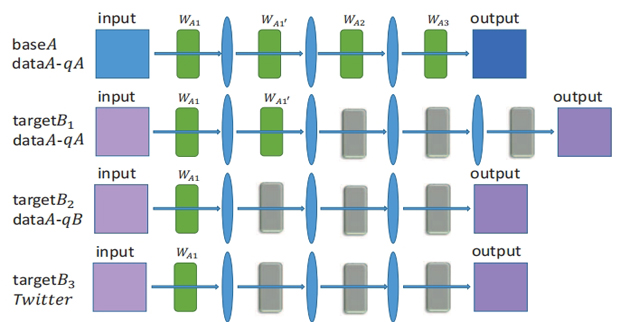 ICCVCompression Artifacts Reduction by a Deep Convolutional Network
ICCVCompression Artifacts Reduction by a Deep Convolutional Network时间:2015年丨作者:Chao Dong, Yubin Deng, Chen Change Loy, Xiaoou Tang
Lossy compression introduces complex compression artifacts, particularly the blocking artifacts, ringing effects and blurring. Existing algorithms either focus on removing blocking artifacts and produce blurred output, or restores sharpened images that are accompanied with ringing effects. Inspired by the deep convolutional networks (DCN) on super-resolution, we formulate a compact and efficient network for seamless attenuation of different compression artifacts. We also demonstrate that a deeper model can be effectively trained with the features learned in a shallow network. Following a similar "easy to hard" idea, we systematically investigate several practical transfer settings and show the effectiveness of transfer learning in low level vision problems. Our method shows superior performance than the state-of-the-arts both on the benchmark datasets and the real-world use cases (i.e. Twitter).
了解更多