





 返回
返回- 核心技术
- 以原创技术体系为根基,SenseCore商汤AI大装置为核心基座,布局多领域、多方向前沿研究,
快速打通AI在各个垂直场景中的应用,向行业赋能。
- 01物体检测
- 02关键点定位
- 03身份验证
- 04属性识别
- 05图像聚类
- 06真人检测
- 07肖像美颜
- 08车型识别
- 09场景识别
- 10遥感图像解译
- 11服装属性识别
- 12视频摘要
- 13视频内容结构化
- 14短视频标签
- 15文字识别
- 16语音识别
- 17自然语言处理
- 18机器人控制与传感
01 / 018
物体检测
全球领先的通用物体检测算法,能有效检测出图片中的常见物体。

02 / 018
关键点定位
毫秒级别眼、口、鼻轮廓等面部21、106、240 个关键点定位,支持不同精度的面部关键点定位,该技术可适应大角度侧脸、大表情变化、遮挡、模糊、明暗变化等各种实际环境。率先支持移动端 14 点身体关键点定位,通过 RGB 图像输入超实时给出头、肩、腰、腿等位置,可适用于各种大幅度动作。

03 / 018
身份验证
判断两张照片是否为同一人,在百万分之一的误识别下,准确率超过99%。

04 / 018
属性识别
准确识别多种属性类别,例如颜色、形状、类型、性别、表情等。

05 / 018
图像聚类
支持图像快速聚类,可用于智能相册等,让照片管理更直观。

06 / 018
真人检测
检测摄像头前用户是否为真人操作,配合身份认证,为金融等高安全性要求的严肃应用场景提供真人身份验证。能有效分辨高清照片、PS 、三维模型、换脸等仿冒欺诈。我们针对不同场景需求提供定制化的解决方案。

07 / 018
肖像美颜
基于智能图像内容检测定位技术,打造移动端美颜、美妆效果解决方案,让移动互联网娱乐时代有“美”可依。

08 / 018
车型识别
实现各种场景下大量车型的精准识别,克服了不同场景、不同光照和拍摄角度变化的影响。

09 / 018
场景识别
精准识别自然环境下数百种场景、上千种通用物体及其属性,让智能相册管理、照片检索和分类、基于场景内容或者物体的广告推荐等功能更加直观。

10 / 18
遥感图像解译
实现对高空间、时间分辨率卫星影像智能化信息提取,面向土地利用类型分类与典型地物提取,点状、面状目标检测和动态变化监测三大任务。
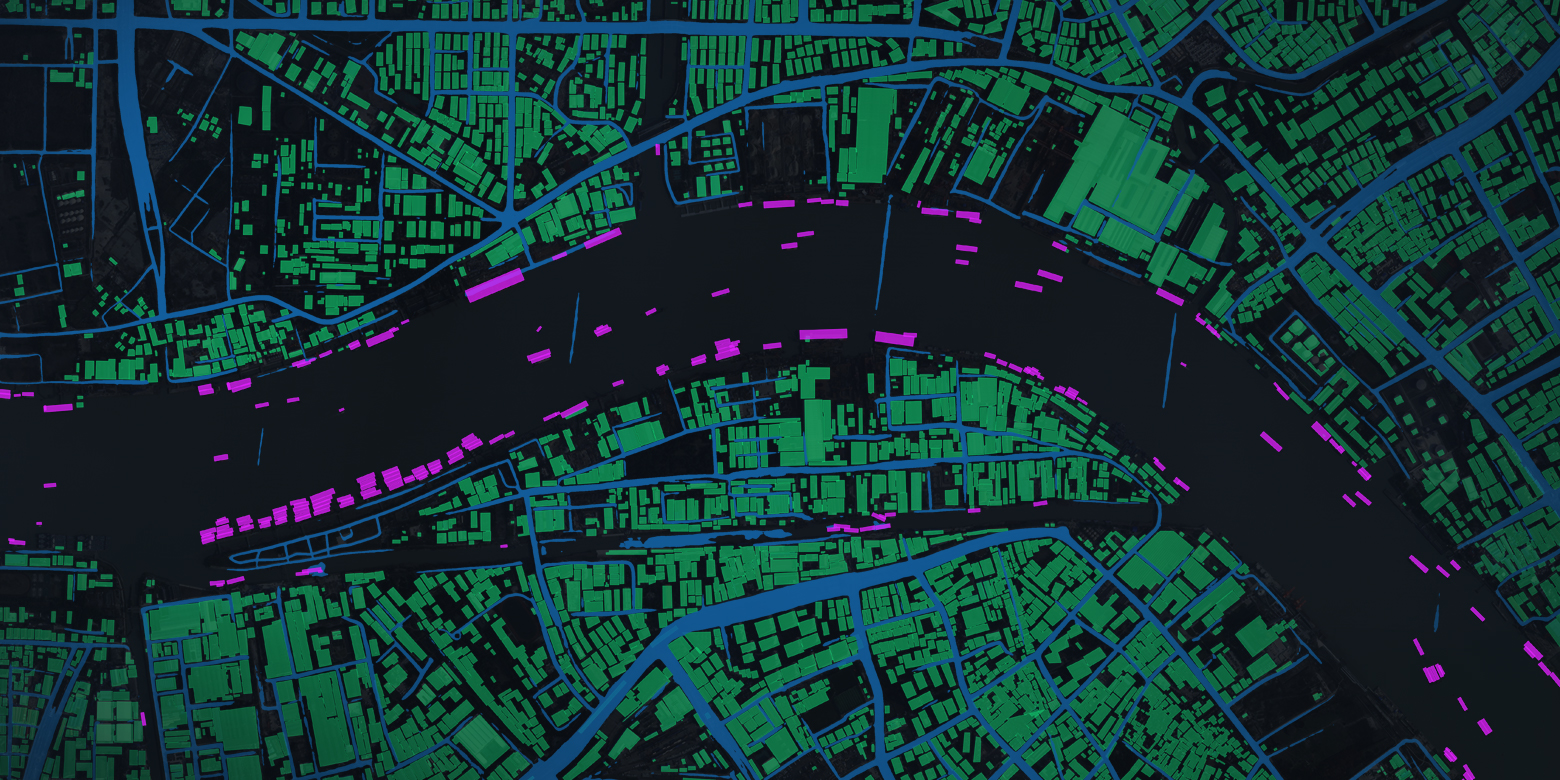
11 / 18
服装属性识别
自动检测和识别图片、视频中的服饰,准确识别服饰品类、花纹、袖型、领型等特征,显著抵抗光照与姿态变化等干扰因素的影响。

12 / 18
视频摘要
基于原创的深度学习算法,智能分析长视频中每个镜头的内容和风格,找出各镜头中的场景和活动等的内在联系,提炼并汇集重点信息,以短视频形式呈现,已经应用于电视、互联网等行业。

13 / 18
视频内容结构化
通过自动分析和提取视频中的有价值素材(比如时尚服饰、场景、商标、商品和行为等),提供丰富的结构化信息,可用于高效的视频素材管理和精准营销。

14 / 18
短视频标签
基于业内领先的大规模多标签算法,自动理解视频的内容,自动生成文本标签,帮助提升视频搜索和推荐的精准度。拥有完善的标签体系,已经落地于移动互联网、电视、广告等多个行业。

15 / 18
文字识别
a)自然场景类:自动提取复杂的自然场景图片中的文字信息。
b)卡证类:在各种拍摄环境下,自动提取卡证图像中的文字信息。
c)票据类:提供不限版式的多种类票据的识别,并根据所在位置自动组织结构。

16 / 18
语音识别
a) 语音识别:自动将音频内容转化为文字信息。
b) 关键词检测:处于休眠状态下的设备通过唤醒直接进入语音交互,或者通过指令词识别控制智能设备。
c) 声纹识别:通过独特的音频特征识别和确认说话人身份。

17 / 18
自然语言处理
a) 自然语言理解和生成:文本表示学习,基于知识的语义理解,可控的文本生成等方向。
b) 对话系统:任务导向型对话系统,知识问答多轮对话系统。

18 / 18
机器人控制与传感
a) 机器人仿真平台:
利用机器人仿真平台灵活改变实验设置,快速获取所需数据,从而对自主抓取策略与机器学习算法进行有效测试和验证。仿真平台采用模块化的架构,关键模块可根据应用需要进行更新和替换,仿真中的关键数据可存取。
b) 3D视觉引导的机器人随机分拣技术:
通过分析 3D 视觉信号精确估计复杂场景中堆叠物体的 6D 姿态,通过碰撞检测和运动规划算法引导机器人以指定的方式抓取堆叠状态下的目标物体。此核心技术可以应用于工业柔性生产装配、上下料、物流分拣、码垛、拆垛等行业领域。
c) 视觉驱动的机械臂物体操作技术:
通过深度学习和强化学习方法使机械臂可以进行自主学习。基于视觉传感器驱动的多物体操作任务(如物体的抓取、放置和零件装配)可以有效地降低硬件和系统集成成本。同时,算法可以在仿真环境下采集训练样本然后迁移至现实环境,从而减少现场调试开销。此项技术提升了机器人在定制化产品智能工业生产线以及多品类物体的物流分拣等工业场景中的灵活性。

01 / 018
物体检测
全球领先的通用物体检测算法,能有效检测出图片中的常见物体。
02 / 018
关键点定位
毫秒级别眼、口、鼻轮廓等面部21、106、240 个关键点定位,支持不同精度的面部关键点定位,该技术可适应大角度侧脸、大表情变化、遮挡、模糊、明暗变化等各种实际环境。率先支持移动端 14 点身体关键点定位,通过 RGB 图像输入超实时给出头、肩、腰、腿等位置,可适用于各种大幅度动作。
03 / 018
身份验证
判断两张照片是否为同一人,在百万分之一的误识别下,准确率超过99%。
04 / 018
属性识别
准确识别多种属性类别,例如颜色、形状、类型、性别、表情等。
05 / 018
图像聚类
支持图像快速聚类,可用于智能相册等,让照片管理更直观。
06 / 018
真人检测
检测摄像头前用户是否为真人操作,配合身份认证,为金融等高安全性要求的严肃应用场景提供真人身份验证。能有效分辨高清照片、PS 、三维模型、换脸等仿冒欺诈。我们针对不同场景需求提供定制化的解决方案。
07 / 018
肖像美颜
基于智能图像内容检测定位技术,打造移动端美颜、美妆效果解决方案,让移动互联网娱乐时代有“美”可依。
08 / 018
车型识别
实现各种场景下大量车型的精准识别,克服了不同场景、不同光照和拍摄角度变化的影响。
09 / 018
场景识别
精准识别自然环境下数百种场景、上千种通用物体及其属性,让智能相册管理、照片检索和分类、基于场景内容或者物体的广告推荐等功能更加直观。
10 / 18
遥感图像解译
实现对高空间、时间分辨率卫星影像智能化信息提取,面向土地利用类型分类与典型地物提取,点状、面状目标检测和动态变化监测三大任务。
11 / 18
服装属性识别
自动检测和识别图片、视频中的服饰,准确识别服饰品类、花纹、袖型、领型等特征,显著抵抗光照与姿态变化等干扰因素的影响。
12 / 18
视频摘要
基于原创的深度学习算法,智能分析长视频中每个镜头的内容和风格,找出各镜头中的场景和活动等的内在联系,提炼并汇集重点信息,以短视频形式呈现,已经应用于电视、互联网等行业。
13 / 18
视频内容结构化
通过自动分析和提取视频中的有价值素材(比如时尚服饰、场景、商标、商品和行为等),提供丰富的结构化信息,可用于高效的视频素材管理和精准营销。
14 / 18
短视频标签
基于业内领先的大规模多标签算法,自动理解视频的内容,自动生成文本标签,帮助提升视频搜索和推荐的精准度。拥有完善的标签体系,已经落地于移动互联网、电视、广告等多个行业。
15 / 18
文字识别
a)自然场景类:自动提取复杂的自然场景图片中的文字信息。
b)卡证类:在各种拍摄环境下,自动提取卡证图像中的文字信息。
c)票据类:提供不限版式的多种类票据的识别,并根据所在位置自动组织结构。
16 / 18
语音识别
a) 语音识别:自动将音频内容转化为文字信息。
b) 关键词检测:处于休眠状态下的设备通过唤醒直接进入语音交互,或者通过指令词识别控制智能设备。
c) 声纹识别:通过独特的音频特征识别和确认说话人身份。
17 / 18
自然语言处理
a) 自然语言理解和生成:文本表示学习,基于知识的语义理解,可控的文本生成等方向。
b) 对话系统:任务导向型对话系统,知识问答多轮对话系统。
18 / 18
机器人控制与传感
a) 机器人仿真平台:
利用机器人仿真平台灵活改变实验设置,快速获取所需数据,从而对自主抓取策略与机器学习算法进行有效测试和验证。仿真平台采用模块化的架构,关键模块可根据应用需要进行更新和替换,仿真中的关键数据可存取。
b) 3D视觉引导的机器人随机分拣技术:
通过分析 3D 视觉信号精确估计复杂场景中堆叠物体的 6D 姿态,通过碰撞检测和运动规划算法引导机器人以指定的方式抓取堆叠状态下的目标物体。此核心技术可以应用于工业柔性生产装配、上下料、物流分拣、码垛、拆垛等行业领域。
c) 视觉驱动的机械臂物体操作技术:
通过深度学习和强化学习方法使机械臂可以进行自主学习。基于视觉传感器驱动的多物体操作任务(如物体的抓取、放置和零件装配)可以有效地降低硬件和系统集成成本。同时,算法可以在仿真环境下采集训练样本然后迁移至现实环境,从而减少现场调试开销。此项技术提升了机器人在定制化产品智能工业生产线以及多品类物体的物流分拣等工业场景中的灵活性。

